TS-LSTM and temporal-inception: Exploiting spatiotemporal dynamics for activity recognition
Abstract
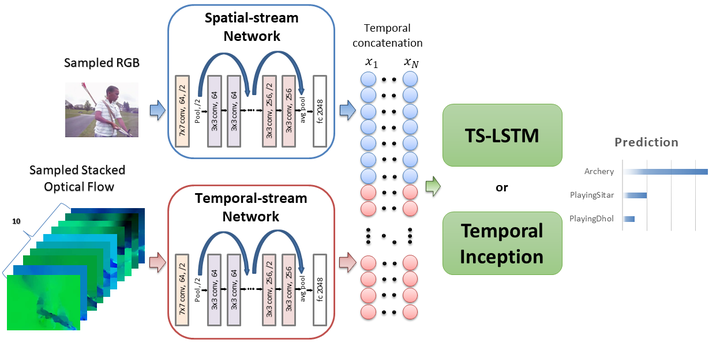
Recent two-stream deep Convolutional Neural Networks (ConvNets) have made significant progress in recognizing human actions in videos. Despite their success, methods extending the basic two-stream ConvNet have not systematically explored possible network architectures to further exploit spatiotemporal dynamics within video sequences. Further, such networks often use different baseline two-stream networks. Therefore, the differences and the distinguishing factors between various methods using Recurrent Neural Networks (RNN) or Convolutional Neural Networks on temporally-constructed feature vectors (Temporal-ConvNets) are unclear. In this work, we would like to answer the question, Given the spatial and motion feature representations over time, what is the best way to exploit the temporal information? Toward this end, we first demonstrate a strong baseline two-stream ConvNet using ResNet-101. We use this baseline to thoroughly examine the use of both RNNs and Temporal-ConvNets for extracting spatiotemporal information. Building upon our experimental results, we then propose and investigate two different networks to further integrate spatiotemporal information, which are (1) Temporal Segment RNN and (2) Inception-style Temporal-ConvNet. We demonstrate that using both RNNs (with LSTMs) and Temporal-ConvNets on spatiotemporal feature matrices are able to exploit spatiotemporal dynamics to improve the overall performance. Our analysis identifies specific limitations for each method that could form the basis of future work. Our experimental results on UCF101 and HMDB51 datasets achieve comparable state-of-the-art performances, 94.1% and 69.0%, respectively, without requiring extensive temporal augmentation or end-to-end training.
Demo Videos
Please check our GitHub.
Resources
Other Links:
Citation
Chih-Yao Ma*, Min-Hung Chen*, Zsolt Kira, and Ghassan AlRegib, “TS-LSTM and temporal-inception: Exploiting spatiotemporal dynamics for activity recognition”, Signal Processing: Image Communication (SPIC), 2019. (*equal contribution)
BibTex
@article{ma2019ts,
title={TS-LSTM and temporal-inception: Exploiting spatiotemporal dynamics for activity recognition},
author={Ma, Chih-Yao and Chen, Min-Hung and Kira, Zsolt and AlRegib, Ghassan},
journal={Signal Processing: Image Communication},
volume={71},
pages={76--87},
year={2019},
publisher={Elsevier}
}
Members
Georgia Institute of Technology
 |  |  |  |
|---|