About Me
My name is Min-Hung (Steve) Chen (陳敏弘 in Chinese). I am a Staff Research Scientist at NVIDIA Research Taiwan, working on Vision+X Multimodal AI. I received my Ph.D. degree from Georgia Tech, advised by Prof. Ghassan AlRegib and in collaboration with Prof. Zsolt Kira. Before joining NVIDIA, I was working at Microsoft Azure AI and MediaTek AI, respectively.
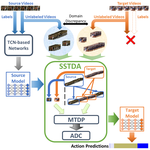
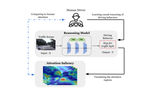
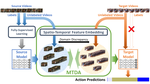
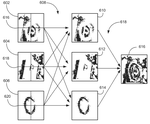
My research interest is mainly Multimodal AI, including Vision-Language, 4D (video+depth) Understanding, Efficient Deep Learning, VLA, and Transformer. I am also interested in Learning without Fully Supervision, including domain adaptation, transfer learning, continual learning, X-supervised learning, etc.
[Recruiting] NVIDIA Taiwan is hiring Research Scientist (fulltime & internship). I am also open to research collaboration. Feel free to contact me if you are interested.
[Note] The Projects, Talks, and Publications Sections are out of date. Please mainly check the News Section.
Interests
- Multimodal
- Video Understanding
- Efficient Deep Learning
- Vision-Language-Action
- Transfer Learning
- Vision Transformer
- Computer Vision
Education
PhD in Electrical and Computer Engineering, 2020
Georgia Institute of Technology
MSc in Integrated Circuits and Systems, 2012
National Taiwan University
BSc in Electrical Engineering, 2010
National Taiwan University