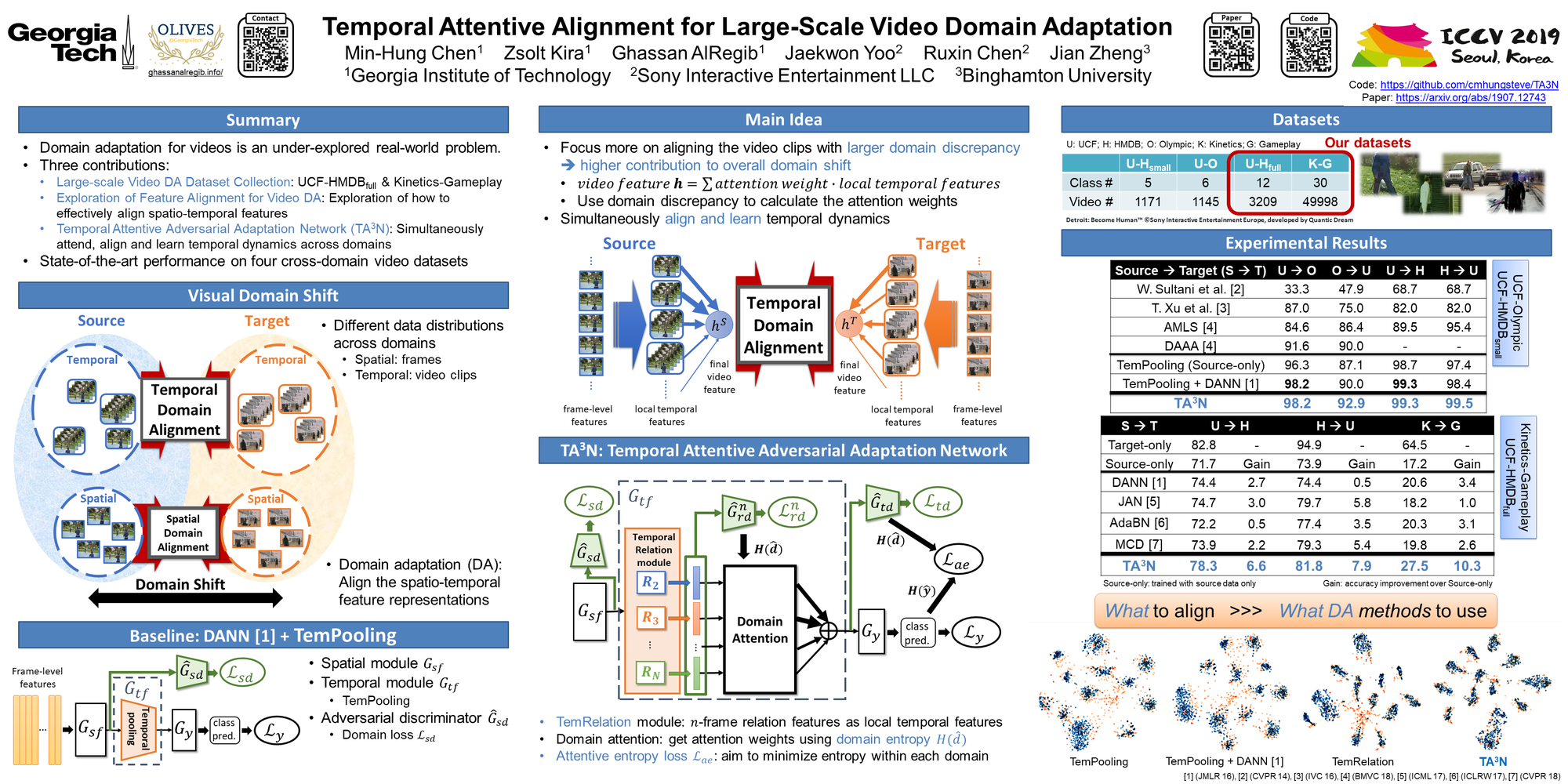
Temporal Attentive Alignment for Video Domain Adaptation
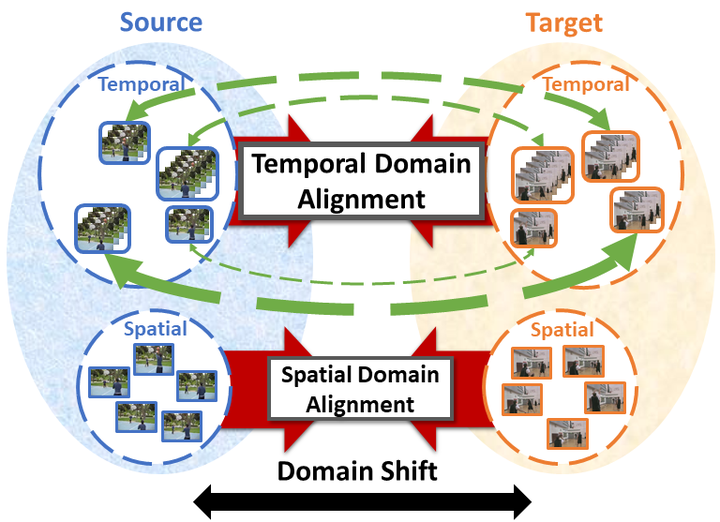
Motivation
Although various image-based domain adaptation (DA) techniques have been proposed in recent years, domain shift in videos is still not well-explored. Furthermore, there do not exist well-organized datasets to evaluate and benchmark the performance of DA algorithms for videos. Therefore, new datasets and approaches for video DA are desired.
Challenges
Videos can suffer from domain shift along both the spatial and temporal directions, bringing the need of alignment for embedded feature spaces along both directions. However, most DA approaches focus on spatial direction only.
Our Approaches
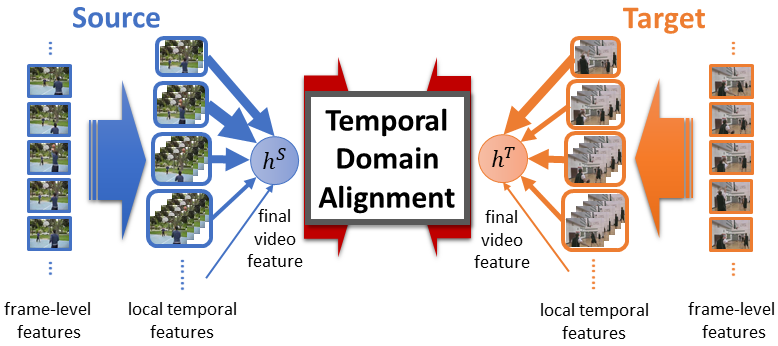
We propose Temporal Attentive Adversarial Adaptation Network (TA3N) to simultaneously attend, align and learn temporal dynamics across domains. TA3N contains the following components:
- TemRelation module: learn various local temporal features embedded with relation information in different temporal scales
- Domain attention mechanism: align local features with larger domain discrepancy (i.e. contribute more to the overall domain shift)
- Assign local features with attention weights calculated using domain entropy
Results
We evaluate both small- and large-scale datasets, and achieve the state-of-the-art performance:
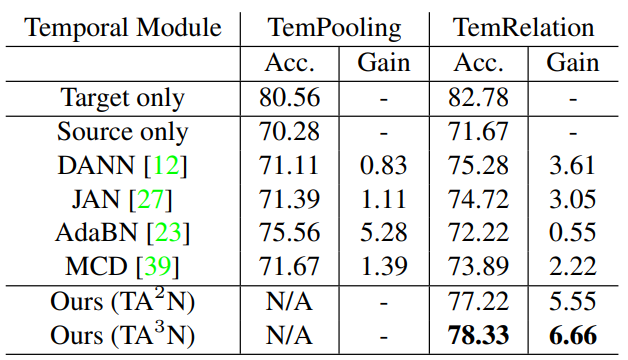
- Quantitative results:
![]()
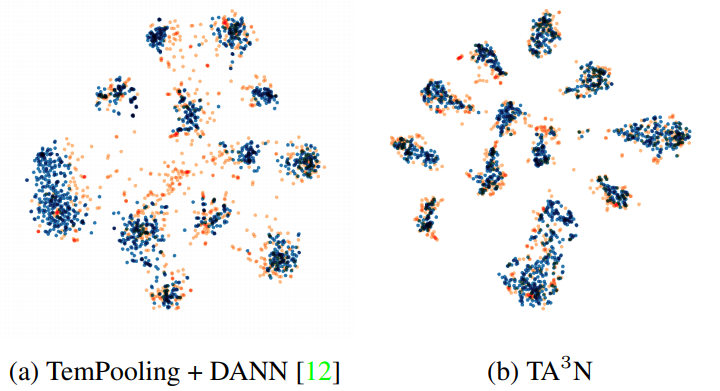
The comparison of accuracy (%) with other approaches on UCF-HMDBfull (UCF –> HMDB). - Qualitative results:
![]()
The comparison of t-SNE visualization between image-based DA and our approach (blue: source, orange: target).
Please check our paper for more results.
Videos
ICCV'19 Oral Presentation (please turn on closed captions):
ICCV'19 Oral Presentation (officially recorded):
Resources
Papers & Code
Presentations
 |  |
|---|
Other Links
- CVF Open Access [ ICCV'19 ]
- IEEE Xplore [ ICCV'19 ]
- The workshop on Learning from Unlabeled Videos (LUV) [ CVPRW'19 ]
- ML@GT [ Blog ][ Article ]
Datasets
We propose two large-scale cross-domain action recognition datasets, UCF-HMDBfull and Kinetics-Gameplay.


To download the dataset, please visit our
GitHub.
Feel free to check our
paper for more dataset details.
Related Publications
If you find this project useful, please cite our papers:
- Min-Hung Chen, Zsolt Kira, Ghassan AlRegib, Jaekwon Yoo, Ruxin Chen, and Jian Zheng, “Temporal Attentive Alignment for Large-Scale Video Domain Adaptation”, IEEE International Conference on Computer Vision (ICCV), 2019 [Oral (acceptance rate: 4.6%), travel grant awarded].
- Min-Hung Chen, Zsolt Kira, and Ghassan AlRegib, “Temporal Attentive Alignment for Video Domain Adaptation”, CVPR Workshop on Learning from Unlabeled Videos (LUV), 2019.
BibTex
@inproceedings{chen2019temporal,
title={Temporal attentive alignment for large-scale video domain adaptation},
author={Chen, Min-Hung and Kira, Zsolt and AlRegib, Ghassan and Yoo, Jaekwon and Chen, Ruxin and Zheng, Jian},
booktitle={IEEE International Conference on Computer Vision (ICCV)},
year={2019}
}
@article{chen2019taaan,
title={Temporal Attentive Alignment for Video Domain Adaptation},
author={Chen, Min-Hung and Kira, Zsolt and AlRegib, Ghassan},
journal={CVPR Workshop on Learning from Unlabeled Videos},
year={2019},
url={https://arxiv.org/abs/1905.10861}
}
Members
1Georgia Institute of Technology 2Sony Interactive Entertainment LLC 3Binghamton University
*work partially done as a SIE intern
 |  |  |  | |  |
|---|
Publications
Temporal Attentive Alignment for Large-Scale Video Domain Adaptation
Talks
Temporal Attentive Alignment for Large-Scale Video Domain Adaptation
