Temporal Attentive Alignment for Large-Scale Video Domain Adaptation
Abstract
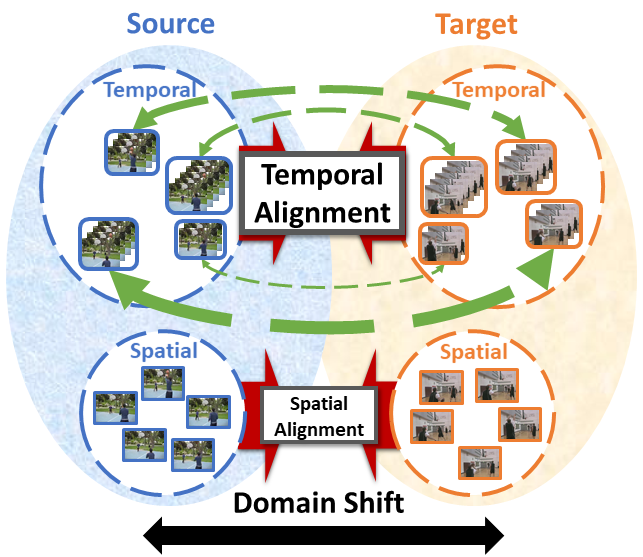
Although various image-based domain adaptation (DA) techniques have been proposed in recent years, domain shift in videos is still not well-explored. Most previous works only evaluate performance on small-scale datasets which are saturated. Therefore, we first propose two large-scale video DA datasets with much larger domain discrepancy, UCF-HMDBfull and Kinetics-Gameplay. Second, we investigate different DA integration methods for videos, and show that simultaneously aligning and learning temporal dynamics achieves effective alignment even without sophisticated DA methods. Finally, we propose Temporal Attentive Adversarial Adaptation Network (TA3N), which explicitly attends to the temporal dynamics using domain discrepancy for more effective domain alignment, achieving state-of-the-art performance on four video DA datasets (e.g. 7.9% accuracy gain over “Source only” from 73.9% to 81.8% on “HMDB–>UCF”, and 10.3% gain on “Kinetics–>Gameplay”).
Videos
Oral Video (please turn on closed captions):
Resources
Other Links:
- CVF Open Access
- IEEE Xplore
- ML@GT Blog
- GT@ICCV'19
- CVPR workshop on Learning from Unlabeled Videos (LUV) [ CVPRW'19 ]
Citation
- Min-Hung Chen, Zsolt Kira, Ghassan AlRegib, Jaekwon Yoo, Ruxin Chen, and Jian Zheng, “Temporal Attentive Alignment for Large-Scale Video Domain Adaptation”, IEEE International Conference on Computer Vision (ICCV), 2019 [Oral (acceptance rate: 4.6%), travel grant awarded].
- Min-Hung Chen, Zsolt Kira, and Ghassan AlRegib, “Temporal Attentive Alignment for Video Domain Adaptation”, CVPR Workshop on Learning from Unlabeled Videos (LUV), 2019.
BibTex
@inproceedings{chen2019temporal,
title={Temporal attentive alignment for large-scale video domain adaptation},
author={Chen, Min-Hung and Kira, Zsolt and AlRegib, Ghassan and Yoo, Jaekwon and Chen, Ruxin and Zheng, Jian},
booktitle={IEEE International Conference on Computer Vision (ICCV)},
year={2019}
}
@article{chen2019taaan,
title={Temporal Attentive Alignment for Video Domain Adaptation},
author={Chen, Min-Hung and Kira, Zsolt and AlRegib, Ghassan},
journal={CVPR Workshop on Learning from Unlabeled Videos},
year={2019},
url={https://arxiv.org/abs/1905.10861}
}
Members
1Georgia Institute of Technology 2Sony Interactive Entertainment LLC 3Binghamton University
*work partially done as a SIE intern
 |  |  |  | |  |
|---|