
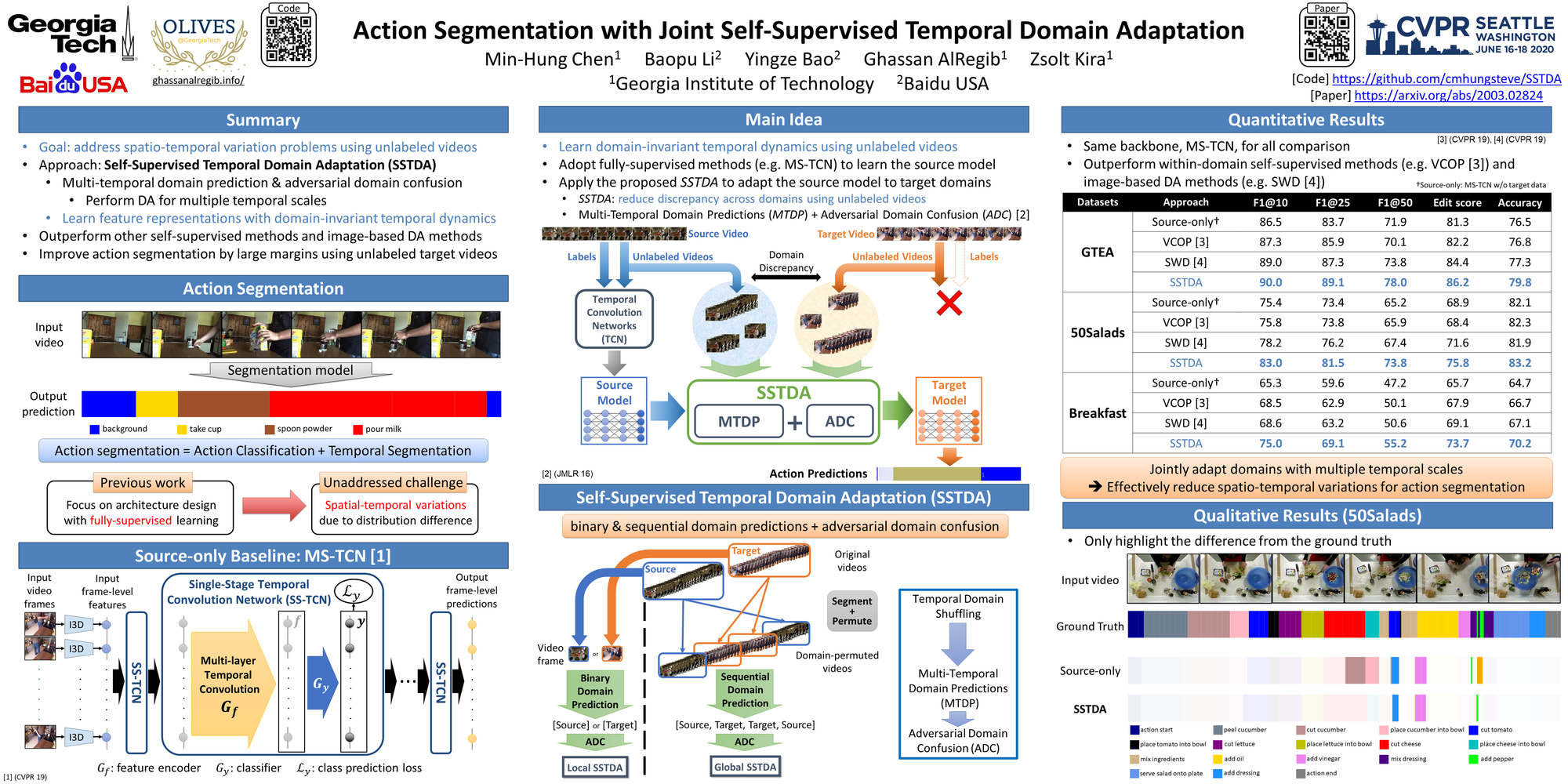
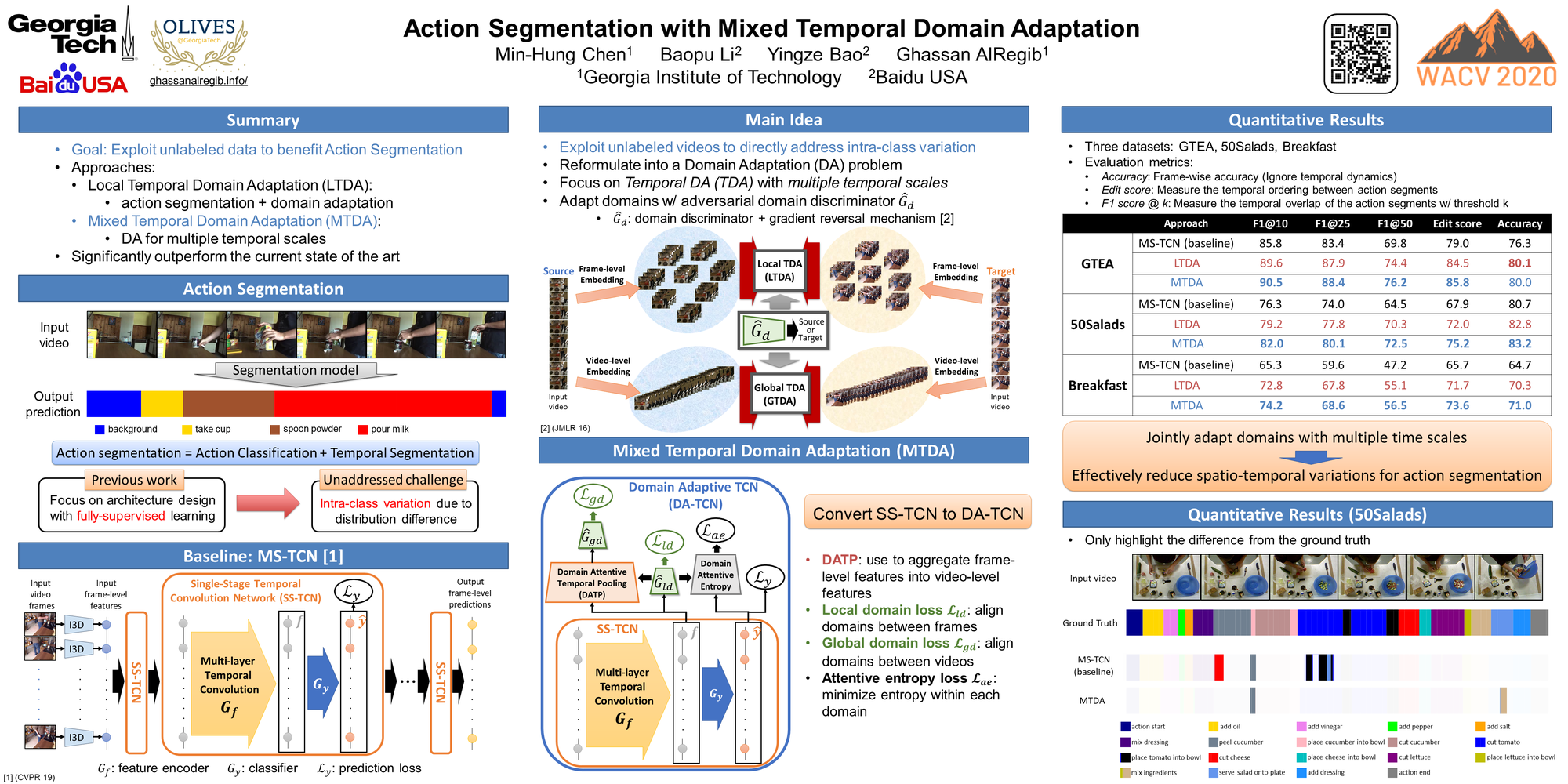
Motivation
Despite the recent progress of fully-supervised action segmentation techniques, the performance is still not fully satisfactory. Exploiting larger-scale labeled data and designing more complicated architectures result in additional annotation and computation costs. Therefore, we aim to exploit auxiliary unlabeled videos, which are comparatively easy to obtain, to improve the performance.
Challenges
One main challenge of utilizing unlabeled videos is the problem of spatio-temporal variations. For example, different people may make tea in different personalized styles even if the given recipe is the same. The intra-class variations cause degraded performance by directly deploying a model trained with different groups of people.
Our Approaches
We exploit unlabeled videos to address this problem by reformulating the action segmentation task as a cross-domain problem with domain discrepancy caused by spatio-temporal variations.
To reduce the discrepancy, we propose two approaches:
- Mixed Temporal Domain Adaptation (MTDA): align the features embedded with local and global temporal dynamics.
![]()
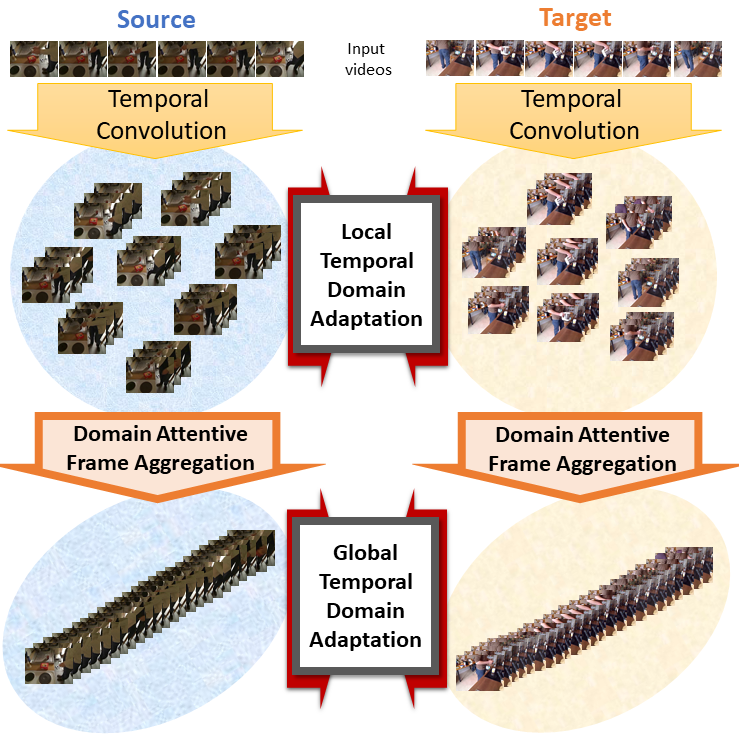
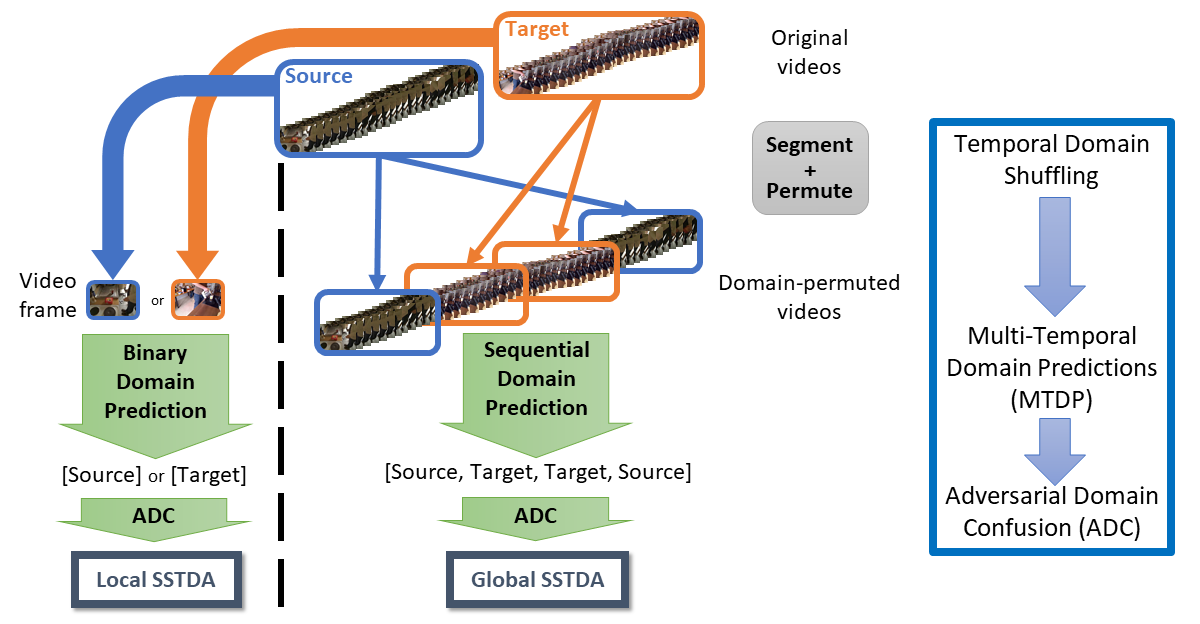
- Self-Supervised Temporal Domain Adaptation (SSTDA): align the feature spaces across multiple temporal scales with self-supervised learning.
![]()
Results
We evaluate three challenging benchmark datasets: GTEA, 50Salads, and Breakfast, and achieve the follows:
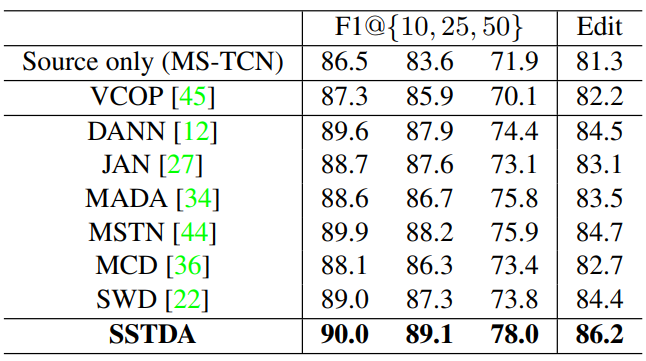
- Outperform other Domain Adaptation (DA) and video-based self-supervised approaches.
![]()
The comparison of different methods that can learn information from unlabeled target videos (on GTEA). - Outperform the current state-of-the-art action segmentation methods by large margins.
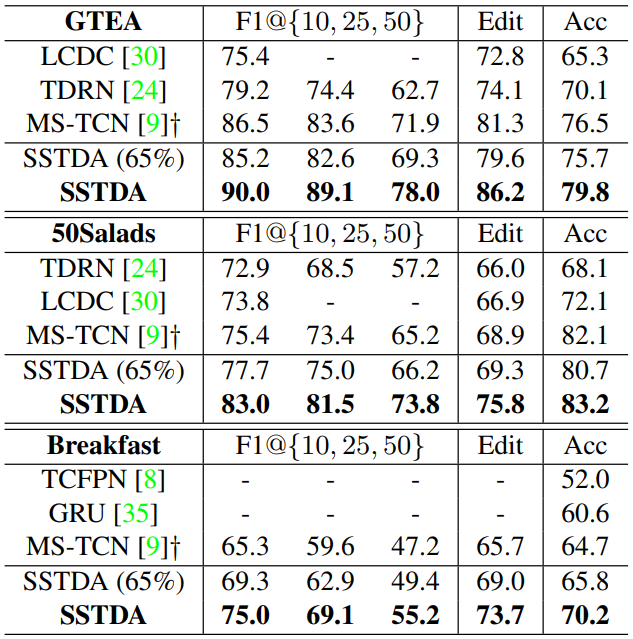
- Achieve comparable performance with fully-supervised methods using only 65% of the labeled training data.
![]()
Comparison with the most recent action segmentation methods on all three datasets. ![]()
The visualization of temporal action segmentation for our methods with color-coding (input example: make coffee)

Please check our papers for more results.
Videos
Overview Introduction:
CVPR'20 Presentation (1-min):
CVPR'20 Presentation (5-min):
WACV'20 Presentation:
Resources
Papers & Code
Presentations
 |  |
|---|
 |  |
|---|
Other Links
Related Publications
If you find this project useful, please cite our papers:
- Min-Hung Chen, Baopu Li, Yingze Bao, Ghassan AlRegib, and Zsolt Kira, “Action Segmentation with Joint Self-Supervised Temporal Domain Adaptation”, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- Min-Hung Chen, Baopu Li, Yingze Bao, and Ghassan AlRegib, “Action Segmentation with Mixed Temporal Domain Adaptation”, IEEE Winter Conference on Applications of Computer Vision (WACV), 2020.
BibTex
@inproceedings{chen2020action,
title={Action Segmentation with Joint Self-Supervised Temporal Domain Adaptation},
author={Chen, Min-Hung and Li, Baopu and Bao, Yingze and AlRegib, Ghassan and Kira, Zsolt},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2020}
}
@inproceedings{chen2020mixed,
title={Action Segmentation with Mixed Temporal Domain Adaptation},
author={Chen, Min-Hung and Li, Baopu and Bao, Yingze and AlRegib, Ghassan},
booktitle={IEEE Winter Conference on Applications of Computer Vision (WACV)},
year={2020}
}
Members
1Georgia Institute of Technology 2Baidu USA
*work done during an internship at Baidu USA
 |  |  |  |  |
|---|
Publications
Action Segmentation with Joint Self-Supervised Temporal Domain Adaptation
Action Segmentation with Mixed Temporal Domain Adaptation
Talks
Action Segmentation with Joint Self-Supervised Temporal Domain Adaptation
